一、论文内容
详细调研了32篇关于视频生成的论文,以确定决定AIGC视频生成质量的关键架构组件和训练策略。
1. 长视频生成方法的架构分类
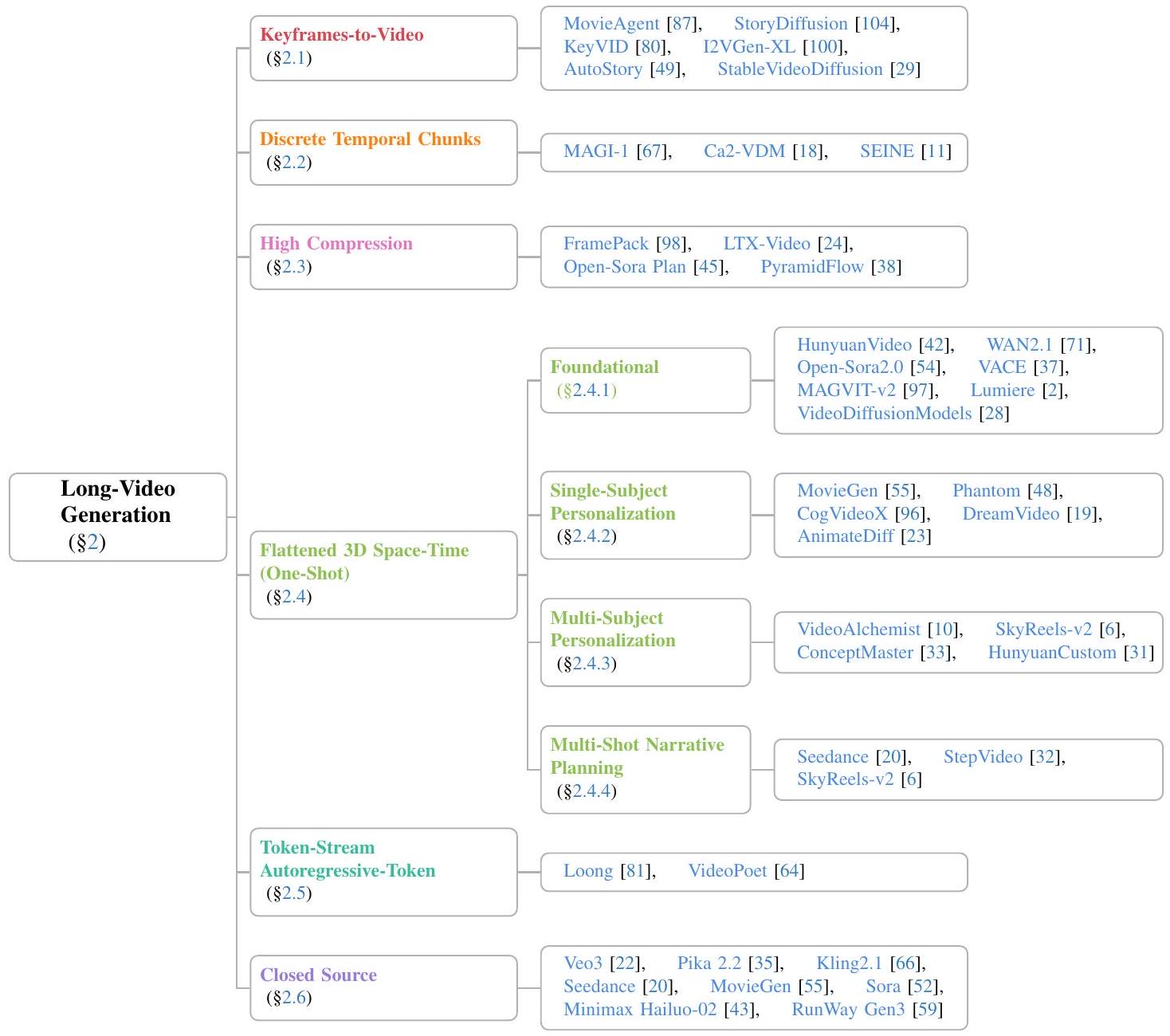
1.1 关键帧生成+插帧
技术核心: 解耦“内容”与“运动”。
阶段一:关键帧生成
技术: 使用强大的文本到图像模型 (如 Stable Diffusion, DALL-E) 或 低频采样的文本到视频模型,生成在时间上稀疏但内容上关键的画面。这些帧定义了场景的主要布局、主体和语义。此阶段专注于空间域的质量和语义准确性。
阶段二:帧插值/运动生成
技术: 使用视频帧插值模型或运动填充模型。这些模型通常是轻量的,专注于学习两个帧之间的光流或潜在运动表示,以生成中间帧。此阶段专注于时间域的连贯性和平滑性。
优: 突破了生成长视频的长度限制;可利用最先进的文生图模型保证画面质量。
劣: 流程串行,总生成时间变长;两个阶段若使用独立模型,可能导致风格、外观不一致;插值错误会引入不自然的运动。
1.2 分块生成与拼接
技术核心: 分治,将长视频分解为可并行处理的独立短片段。
将长序列划分为多个不重叠的时间块。每个块由一个共享权重的视频生成模型独立生成。所有块生成后,在时间维度上进行拼接。
优: 大幅降低峰值显存占用,是生成长视频最实用的方法之一;天然支持并行生成,加快速度。
劣: 块间一致性仍是核心挑战,即便采用高级训练技巧,也难以达到端到端模型的完美流畅度。
1.3 潜在空间高压缩
技术核心: 降维,在高度压缩的潜在空间中操作,极大减少处理序列的Token数量。
编码:使用如VAE、VQ-VAE或VQ-GAN的编码器,将图像/视频帧压缩到一个高度抽象的潜在表示。压缩比可以非常高(例如,将256px图像压缩为32x32的潜在编码,空间上压缩8倍)。
在潜在空间中生成: 扩散或自回归过程不是在像素空间,而是在这个压缩后的潜在空间中进行。要处理的数据量减少了数十至数百倍。
解码: 最后通过解码器将潜在表示转换回像素空间。
优: 效率的革命性提升,使得在消费级GPU上运行视频生成成为可能。
劣: 压缩必然伴随信息损失。高压缩会丢失细节,导致纹理模糊、高频信息(如精细边缘、文字)失真,以及快速运动中的伪影。
1.4 端到端时空建模
技术核心: 统一建模,将时间视为一个统一的维度,用3D卷积/注意力共同建模时空信息。
3D U-Net / DiT: 模型 backbone 使用 3D U-Net / DiT。patch不再是2D的图像块,而是3D的时空立方体。模型一次性看到一个小的时间片段,从而能够联合理解空间外观和时间运动。
位置编码: 使用3D RoPE等高级位置编码,同时编码空间位置和时间位置。
代表: Sora 的技术报告表明其属于此类范式。它通过将视频转换为时空patch的序列,然后用类似GPT的Transformer进行生成。
优: 理论上质量最高的方法。能产生最连贯、物理最合理的运动,因为它能直接对时空联合分布进行建模。
劣: 计算和内存开销巨大。序列长度是 帧数 × 高度 × 宽度,这限制了其直接生成的视频长度和分辨率。是“梦想架构”,但目前对算力要求极高。
1.5 自回归Token预测
技术核心:范式转换,将视频生成视为“下一个token预测”问题,统一文本和视频的生成范式。
Token化: 使用强大的视觉分词器(如MAGVIT-v2, VQ-GAN)将每帧图像转换为一系列离散的token。
序列建模: 将文本token和视频token拼接成一个长的多模态序列。
自回归生成: 使用一个Decoder-Only的大型Transformer(如GPT)来按顺序预测下一个视觉token。
代表: Google 的 VideoPoet 是典型代表。
优: 架构极其简洁统一;可轻松利用来自LLM的 scaling law 和优化技巧;理论上可生成无限长视频。
劣: 自回归生成速度慢(无法并行解码);错误会累积;对分词器的质量依赖极高。
2. 长视频生成方法的关键架构组件
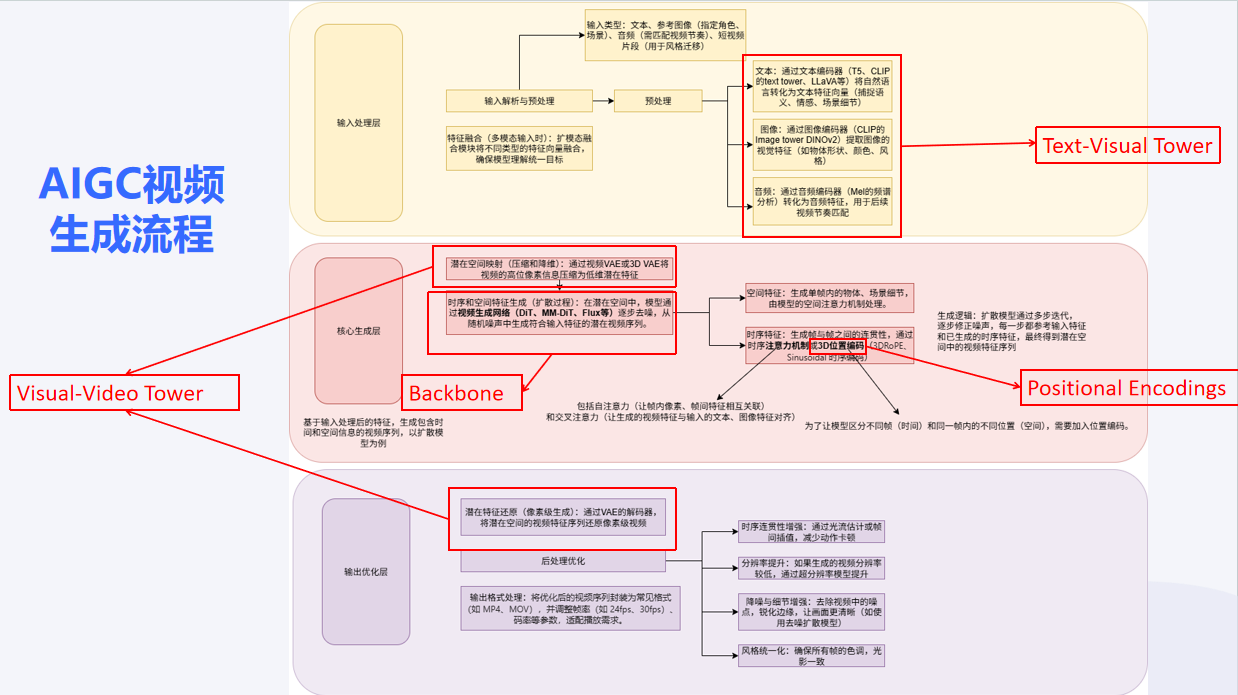
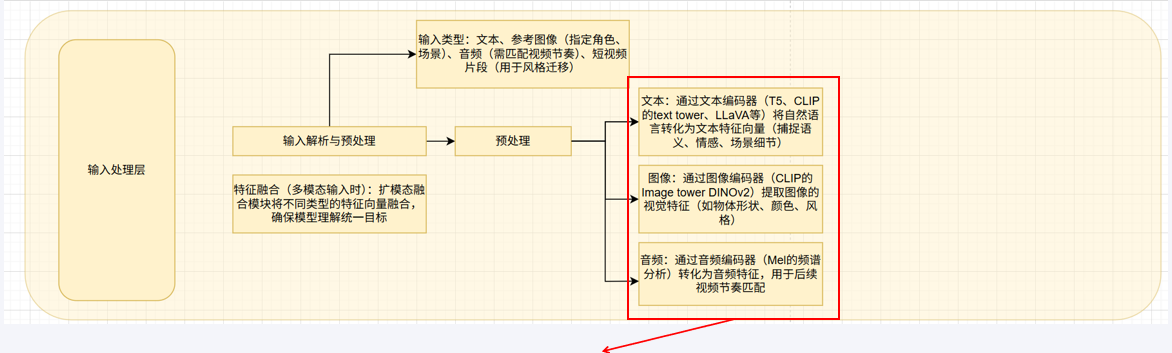
Text-Visual Tower :
负责理解和处理条件输入(文本、图像、音频)的组件集合
从“T5系列+CLIP”组合转向“多模态大语言模型 (MLLM)”。
旧范式 : 使用 T5/T5-XXL/umT5 等强大文本编码器与 CLIP 结合。T5负责深度语义理解,CLIP负责图文对齐。
趋势: 使用 MLLM(如 LLaVA, Qwen2-VL)单一模型替代上述组合。MLLM不仅能理解复杂语义,还能更好地理解空间指令(如“左边的猫”),实现更精细的视觉-文本特征对齐,减少语义漂移。HunyuanVideo 是这一趋势的代表。
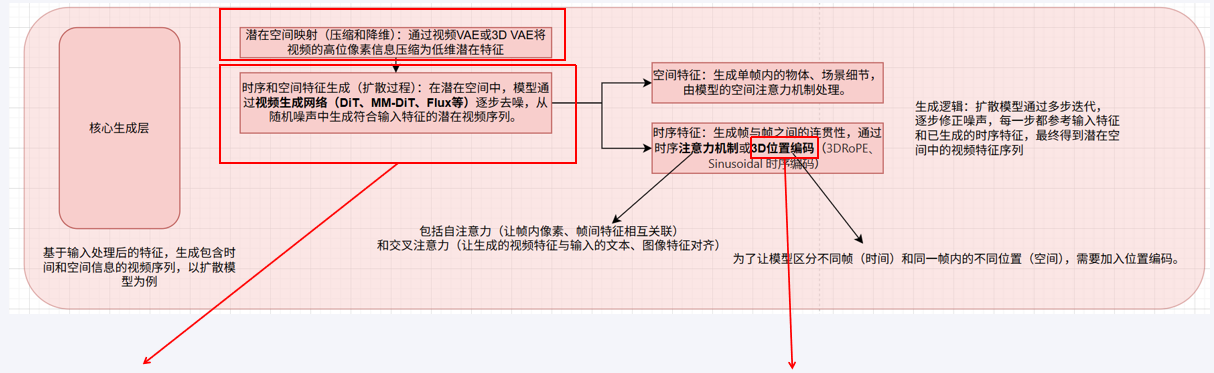
Backbone:
3D U-Net —–> DiT —-> MM-DiT —-> Flux-MM-DiT
Decoder-only Transformer LLM
像GPT那样的纯自回归Transformer,代表模型(如VideoPoet)将视频生成视为“下一个token预测”问题。
Positional Encodings:
Sinusoidal/RoPE ——–> 3DRoPE
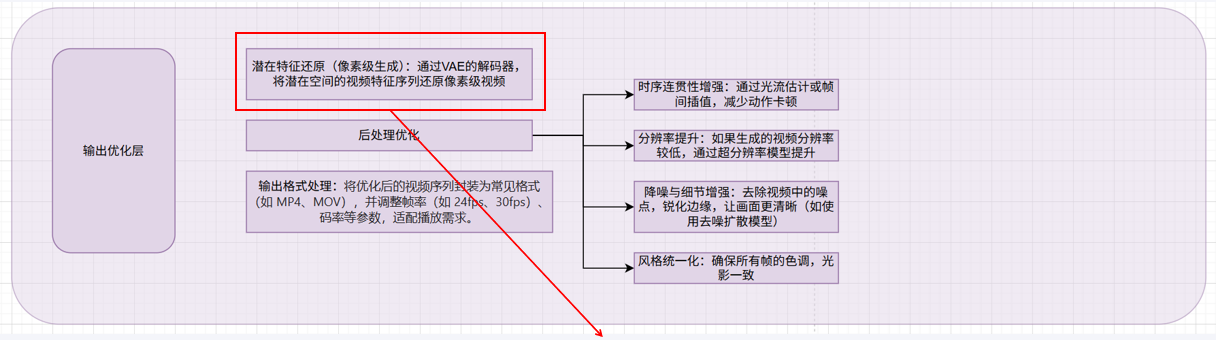
Visual-Video Tower :
负责将内部表示转换为最终视频的组件
SD 2D VAE ————–> 3D VAE / Video VAE
从Stable Diffusion继承的2D编码器 前沿模型专用,能更好地压缩和重建时间信息,生成更连贯的视频。
MAGVIT-v2: 视频Tokenize模型,用于自回归方案。
双VAE 架构成为新趋势。使用两个独立的编码器分别处理静态外观特征和时序动态特征。
解耦外观与运动,使模型学习更专注。显著降低训练成本(如Open-Sora 2.0降低5-10倍)。更好地保持多主体身份一致性(如VideoAlchemist)。
3. 前沿AIGC视频生成工具
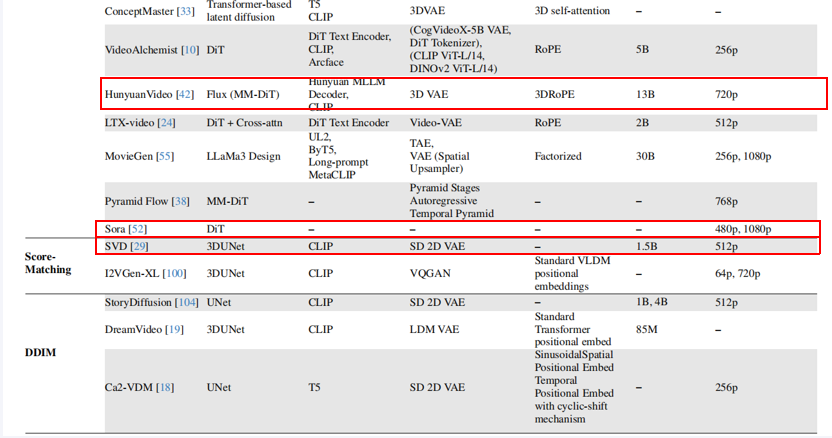
HunyuanVideo (腾讯):使用 Flux-MM-DiT 架构。其最大特点是使用自研的 Hunyuan MLLM 作为文本编码器,在理解中文语境和复杂指令方面表现出色。也采用了3D VAE和3D RoPE。参数量13B,能生成720p的高清视频。
Sora (OpenAI):尽管细节未完全公开,但已知其使用 Diffusion Transformer (DiT) 作为核心架构。它的一大革命性能力是支持可变分辨率、持续时间和宽高比的生成,这与之前固定尺寸的模型截然不同。能生成长达1分钟的1080p高清视频,具有惊人的长程连贯性和世界模拟能力(如物体符合物理规律运动)。
Stable Video Diffusion (SVD) (Stability AI):目前最流行、应用最广的开源视频生成模型之一。它是Stable Diffusion的图像到视频专门化版本。基于3D U-Net架构,是一个图像到视频的模型,这意味着你需要先有一张图片,它才能生成一段视频。它采用了帧间插值技术来生成长视频。支持生成14或25帧的576x1024分辨率视频。虽然在绝对质量上不如Sora,但其生成速度和质量在开源模型中非常均衡。
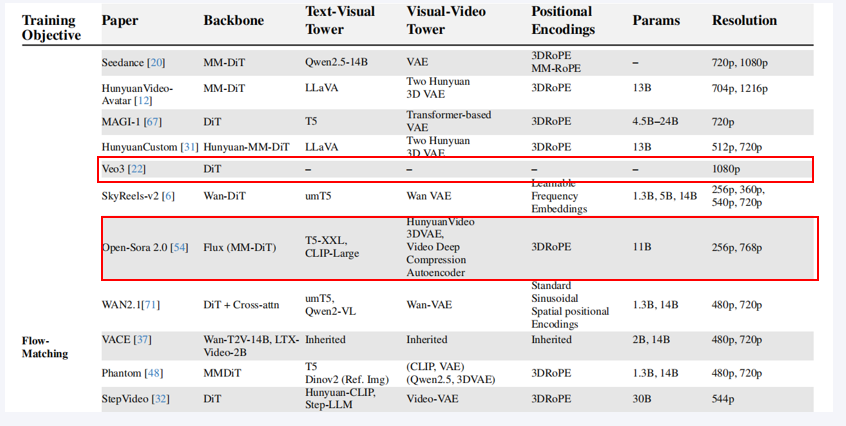
Veo 3 (Google DeepMind):基于DiT架构,并集成了多种先进的编码技术和训练目标。它旨在生成高质量的1080p视频,并同样支持长视频生成。官方演示显示其能生成超过一分钟的高质量、连贯视频。它特别强调了对复杂文本指令的精确理解和 cinematic 质量。
Open-Sora :复现Sora。旨在通过完全开源的方式,逐步实现与Sora类似的能力。采用了最先进的Flux-MM-DiT作为主干网络,并使用了双VAE设计(Hunyuan 3DVAE + 自编码器)来处理外观和运动。它代表了开源社区的顶尖技术水平。支持生成256p 到 768p 分辨率的视频,参数量达到11B。其目标是不断追赶闭源模型的性能。
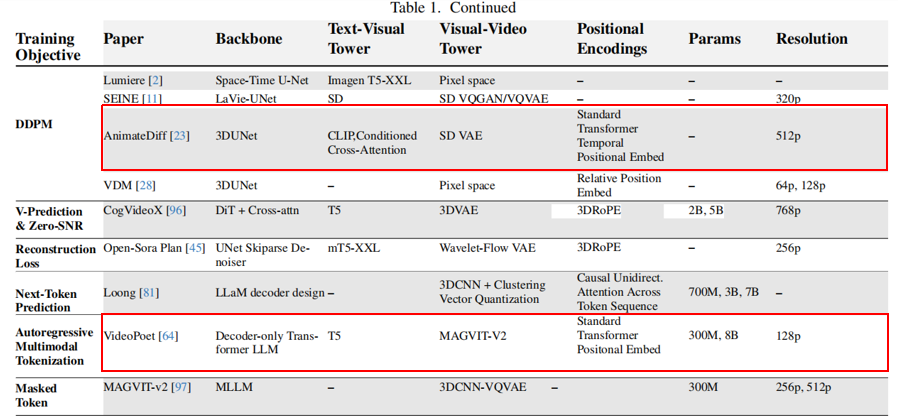
AnimateDiff:基于3D U-Net,它可以被注入到任何基于Stable Diffusion的图像模型中,从而让静态图像模型“动起来”。不直接决定分辨率,而是依赖于底层图像模型的能力。极大地扩展了现有图像模型的能力,用户可以使用自己喜欢的任何图像模型来创建视频,降低了视频生成的门槛。
VideoPoet (Google):非扩散模型路径。它证明了自回归方案在视频生成上同样有效。使用纯Transformer架构(Decoder-Only LLM),将视频和音频都转换为离散的token,像生成文本一样生成视频。支持生成多种分辨率和长宽比的视频,并能完成视频风格化、修复等多种任务。提供了一种与扩散模型截然不同的技术思路,架构非常简洁统一,潜力巨大。
二、延伸学习
深度学习基础都忘光了
1. backbone -> 图像扩散模型 -> 3D U-Net -> CNN -> DiT -> Transformer
2. VAE
3. T5/CLIP/MLLM
三、AIGC视频检测点
现代视频生成模型的技术特点,恰恰决定了其输出结果的“指纹”和可检测的漏洞。
| 漏洞类别 | 技术根源 | 具体表现与取证线索 |
|---|---|---|
| 1. 物理不合理性 | 模型对复杂物理规律的理解不完全或近似错误。 | • 光影不一致: 光源方向、物体阴影在帧间发生跳变或不匹配。 • 流体与碰撞异常: 水、火、烟雾的运动违反物理规律;物体碰撞后的运动轨迹不自然。 • 相机模型违背: 生成的相机运动(如晃动、变焦)与真实相机拍摄的动力学特征不符。 |
| 2. 压缩与重构伪影 | 高压缩VAE 导致的高频信息丢失和重建误差。 | • 高频细节缺失: 极细的线条、远处文字、密集纹理出现模糊或混淆。 • 色带与色块: 在平滑的颜色渐变区域出现不自然的色带(Color Banding)。 • 运动模糊失真: 动态模糊效果在整个画面上不一致,或与运动速度不匹配。 |
| 3. 时空不一致性 | 模型在生成长序列时长程依赖建模失败。 | • 帧间闪烁: 物体表面纹理、亮度或颜色出现高频闪烁(Flickering)。 • 物体突变: 物体或人物在序列中突然出现、消失或形态剧变。 • 身份漂移: 生成的人脸身份特征在视频中无法保持完全一致。 |
| 4. 模型指纹溯源 | 不同模型架构和训练数据留下的独特“风格”印记。 | • VAE解码特征: 不同VAE解码器重建的图像在局部纹理、边缘处理方式上存在差异。 • 位置编码模式: 使用3D RoPE的模型与使用正弦编码的模型,其时空关联模式可能不同。 • 纹理风格: 模型训练数据集的偏向会导致生成内容具有特定的纹理或色彩风格。 |